商品期货量化交易-TradingviewPine语言基础课程(九):时间序列
Author: ianzeng123, Created: 2023-02-17 10:17:08, Updated:你做过交易吗,连续高长时间的紧盯着一块屏幕,密切的观察指标的变化,不断地在衡量交易的规律和趋势,决定交易操作,执行并继续观察交易结果,不断地调仓补仓平仓,直至最后交易时间段结束,还需要你进行更为深刻的自身,复盘总结今日某一瞬间的得失。这就是一个交易人,与市场,与大盘,与庄家,与自己的战斗。每天都在不断上演。交易可以量化吗?有时候你会怀疑,怎样利用语言去模拟一个金融市场,无数伴随着每豪每秒的纷繁信号,眼花缭乱的涨跌趋势,怎样去抓取其中的规律,预测未来?这就需要我们深入了解Pine语言对于交易逻辑的处理–时间序列和模型执行。
这两部分的内容其实应该在Pine语言,入门的时候为大家讲解,可是理解起来确实有些困难。因此在为大家讲述完,Pine语言基本语法结构的基础上编写简单的代码,为大家进行更好的展示。
时间序列
首先,我们讲解时间序列,在类型系统中我们粗略的介绍过。时间序列并不是一种数据类型或者格式,时间序列是PINE语言中一种基本结构的概念。用来储存时间上连续变动的值,每个值都对应一个时间点。时间序列这种概念的结构很适合应用于处理、记录随时间变化的一系列数据。
我们知道Pine脚本是基于图表的,图表中展示的最基本的内容就是K线图。时间序列其中每个值都与一个K线Bar的时间戳关联。PINE语言这样设计时间序列,可以在策略代码中很轻松地计算收盘价的累计值,而且不需要使用for之类的循环结构,只用使用PINE语言的内置函数ta.cum()。下面我们举例进行一下解释:
这段代码的意思是,在一个策略周期内,我们设置两个变量,第一个变量v1,赋值为整数1,第二个变量v2是伴随策略周期累加的v1值,然后我们使用plot函数将v1,v2和k线bar的索引,这个内置变量bar.index在图表中展示出来。
v1 = 1
v2 = ta.cum(v1)
plot(v1, title="固定v1")
plot(v2, title="累计v1")
plot(bar_index+1, title="bar序列")
有很多类似ta.cum这样的内置函数可以直接处理时间序列上的数据,例如ta.cum就是把传入的变量在每个K线Bar上对应的值累加起来,接下来我们使用一个图表来方便理解。
| 策略运行时间段 | 内置变量bar_index | 内置变量bar_index + 1 | 固定v1 | 累计v2 |
|---|---|---|---|---|
| 策略运行第一根K线Bar: 0 到 1 分钟 | 0 | 1 | 1 | 1 |
| 策略运行第一根K线Bar: 1 到 2 分钟 | 1 | 2 | 1 | 2 |
| 策略运行第一根K线Bar: 2 到 3 分钟 | 2 | 3 | 1 | 3 |
| 策略运行第一根K线Bar: 3 到 4 分钟 | 3 | 4 | 1 | 4 |
| 策略运行第一根K线Bar: 4 到 5 分钟 | 4 | 5 | 1 | 5 |
可以看到,他们都是时间序列结构,在每根Bar上都有对应的数据。
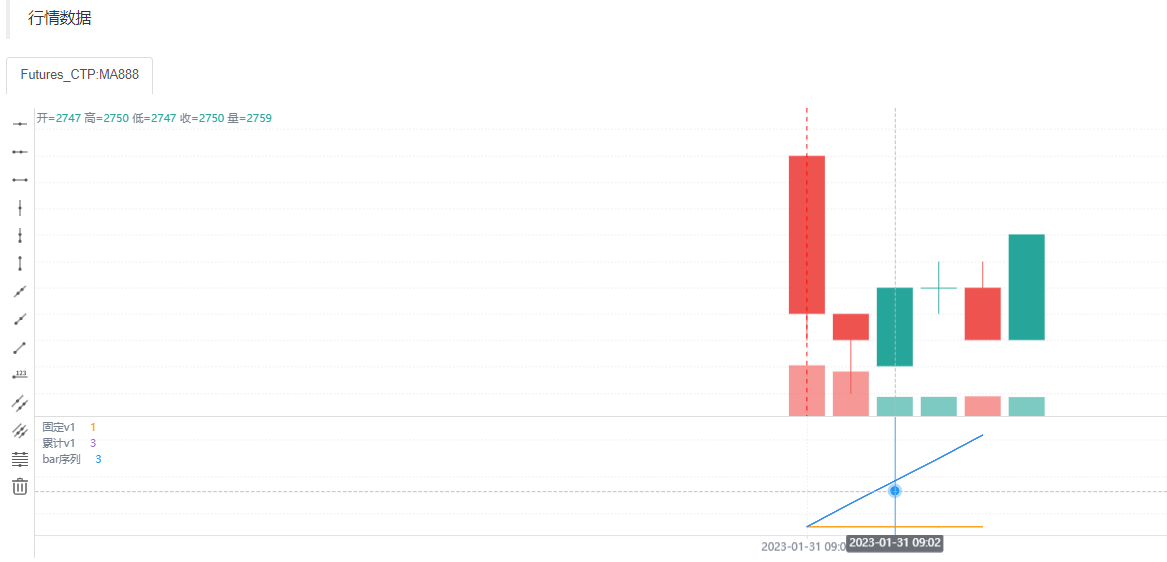
因为固定v1这个变量在每一根Bar上都是1,ta.cum(v1)函数在第一根K线Bar上执行时由于只有第一根Bar,所以计算结果为1,赋值给变量累计v2。
当ta.cum(v1)在第二根K线Bar上执行时,已经有2根K线Bar了(第一根对应的内置变量bar.index是0,第二根对应的内置变量bar.index是1),所以计算结果为2,赋值给变量v2,以此类推。实际上可以观察到v2就是图表中K线Bar的数量,由于K线的索引bar.index是从0开始递增,那么bar.index + 1实际上也就是K线Bar的数量。观察图表也可以看到v2和bar.index确实是重合的。
需要注意的是,虽然时间序列很容易让人想起「数组」这种数据结构,虽然PINE语言也有数组类型。但是它们和时间序列是完全不同的概念。
在时间序列上调用函数的结果也会在时间序列上留下痕迹,同样可以使用[]历史操作符引用之前的值。例如,计算最后10根K线BAR中的最高价的最大值时(不包括当前的K线BAR)。我们可以写为 ta.highest(close, 10)[1],同样也可以写成 ta.highest(close[1], 10)。两者是等价的。
可以用以下代码验证:
strategy("test pine", "test", true)
a = ta.highest(close, 10)[1]
b = ta.highest(close[1], 10)
runtime.log("a",a)
runtime.log("b",b)
PINE语言这样设计时间序列,可以在策略代码中很轻松地进行时间逻辑的运算。但是需要了解其具体的运行机制,我们可以进行一个展示。
pricecum1 = ta.cum(close)
pricecum2 = close // pricecum2 = close+close[1]+close[2]
for i=1 to 2
pricecum2 += close[i]
i += 1
runtime.log("pricecum1:", pricecum1)
runtime.log("pricecum2:", pricecum2)
策略是从09:00准时开始的,用一分钟为K线周期,我们进行五分钟的策略回测(09:00至09:05),因为最后的K线是09:05还没有更新完,所以09:05的数据是不显示的,只能展示四个值(0到1,1到2,2到3,3到4,四个时间段)。在回测日志中,我们可以观察到pricecum1使用ta.cum函数,从策略起始处(0到1)就开始计算累加值,直到(0到4),所以计算了四段k线的累加值。而pricecum2,以三分钟的k线累加值为一个轮回进行循环计算,因为在0到1和1到2处,没有前两个值,即close[1]和close[2],所以第一分钟,和第二分钟的pricecum2为空值,到第三分钟时,pricucum2 = close + close[1] + close[2], 三个值都是实值了,可以进行计算,并且和pricecum1相等。因为pricecum2以3为周期,所以pricecum1和pricecum2在第四分钟两者时不相等的,这个时候pricecum1计算的是0到1,1到2,2到3,3到4,四个时间段的收盘价累加值;而pricecum2计算的是1到2,2到3,3到4,三个时间段的收盘价累加值。这是一个时间序列的例子,大家可以回味下。
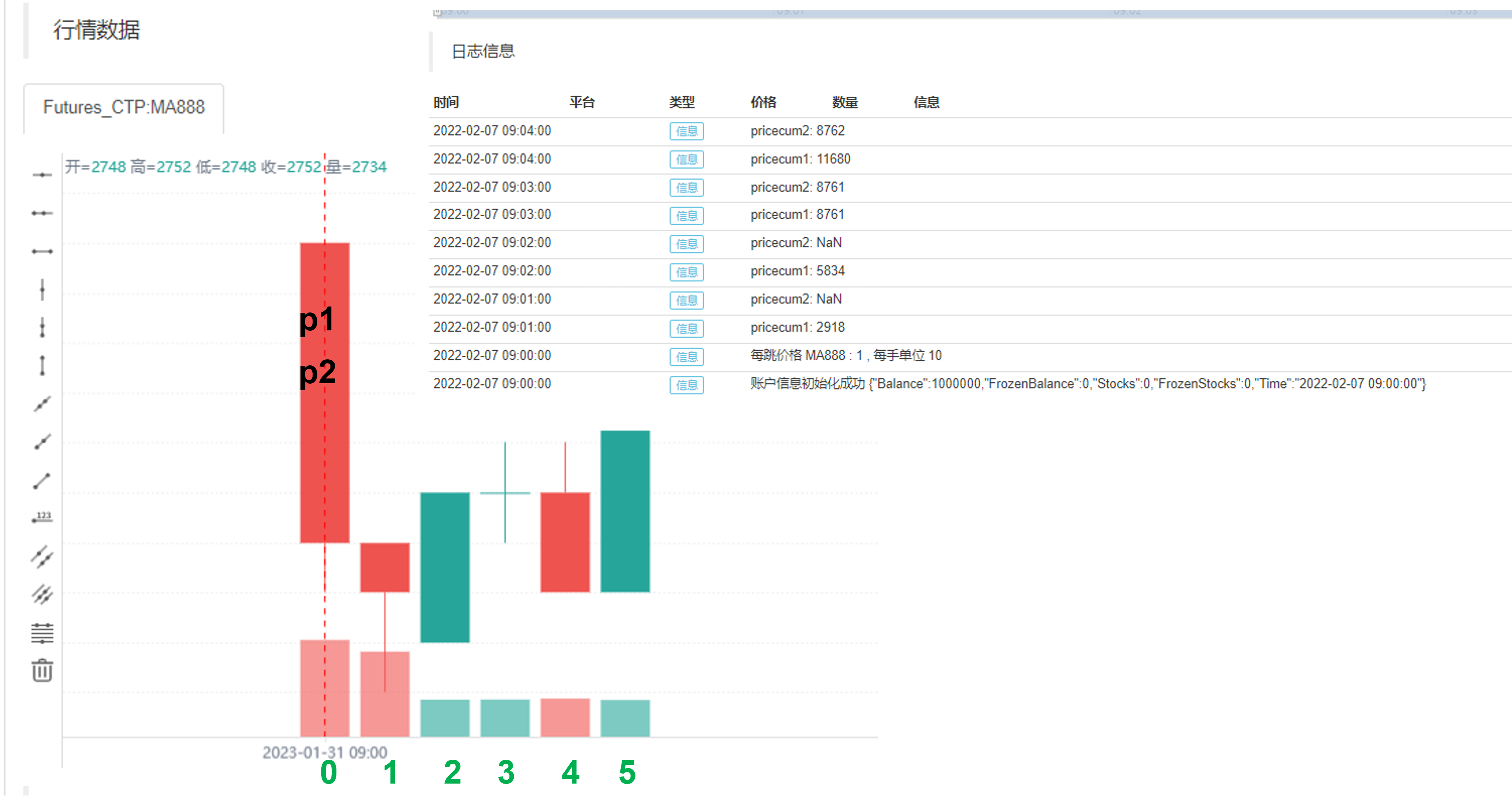
我们可以看到策略从初始值实时更新的时候,是不会使用过去的历史bar,因此如果在策略中你使用了循环语句,去利用过去的指标去判断交易的逻辑。在策略开始的时候,你需要等待循环逻辑走完,才能进行交易的处理。第二点请注意,这里我们选择的是收盘价模型,如果我们这里选择的是实时价模型,进行策略的运行,日志的结果将会是这样。这两者的区别涉及到模型执行机制,我们下节课为大家继续讲解。

- 商品期货量化交易-TradingviewPine语言基础课程(十八):量化交易指标:反趋势指标
- 商品期货量化交易-TradingviewPine语言基础课程(十七):量化交易指标:趋势指标
- 商品期货量化交易-TradingviewPine语言基础课程(十六):交易函数:strategy系列
- 商品期货量化交易-TradingviewPine语言基础课程(十五):数组
- 商品期货量化交易-TradingviewPine语言基础课程(十四):内置函数:math.系列和ta.系列
- 商品期货量化交易-TradingviewPine语言基础课程(十三):自定义函数和内置变量
- 回测比特币
- 商品期货量化交易-TradingviewPine语言基础课程(十二):画图(2)
- 商品期货量化交易-TradingviewPine语言基础课程(十一):画图(1)
- 商品期货量化交易-TradingviewPine语言基础课程(十):模型执行
- 商品期货量化交易-TradingviewPine语言基础课程(八): 条件和循环结构
- 商品期货量化交易-TradingviewPine语言基础课程(七): 运算符
- 商品期货量化交易-TradingviewPine语言基础课程(六):Pine语言类型系统讲解(2):Types
- FMZ平台看穿式监管期货账户开通教程(国泰君安平台)
- 商品期货量化交易-TradingviewPine语言基础课程(五):Pine语言类型系统讲解(1):Forms
- 商品期货量化交易-TradingviewPine语言基础课程(四):Pine语言编辑器窗口和代码结构
- 商品期货量化交易-TradingviewPine语言基础课程(三):FMZ量化平台使用指南(2)
- 商品期货量化交易-TradingviewPine语言基础课程(二):FMZ量化平台使用指南(1)
- 商品期货量化交易-TradingviewPine语言基础课程(一):Pine语言和FMZ量化平台介绍
- 发明者量化交易平台购课送书活动开始啦!