浅谈K线处理的底层机制
Author: ianzeng123, Created: 2023-07-12 16:34:04, Updated: 2023-11-15 19:56:01
浅谈K线处理的底层机制
K线是一种用于表示一段时间内市场价格变动情况的图表。我们获取的k线数据,是根据CTP协议(中国金融期货交易所的交易接口协议)提供的tick数据合成的。作为伴随时间流的k线数组,每根K线包含开盘价、最高价、最低价和收盘价,交易量和持仓量关键数据。虽然我们可以直接使用现成的指标函数比如TA.MA()直接使用k线数据进行技术指标的计算,但这个过程实际上是一个黑盒,我们不能了解具体的底层K线处理机制。然而,了解底层K线的处理机制对于理解技术指标的计算过程和优化算法非常重要。
理解计算过程:了解底层K线的处理机制可以帮助我们理解技术指标的计算过程。通过了解每个步骤的具体实现逻辑和算法,我们可以更好地理解指标是如何被计算出来的,以及每个参数的含义和影响。
优化算法:了解底层K线的处理机制可以帮助我们优化计算算法。通过深入了解K线数据的存储结构、遍历方式以及处理函数的性能特点,我们可以对算法进行改进,提高计算速度和效率。例如,使用更高效的数据结构、采用并行计算等方法,可以加快计算速度,提升策略的实时性。
策略定制:了解底层K线的处理机制可以帮助我们自定义指标和策略。有时,现有的技术指标不能完全满足我们的需求,需要进行定制化开发。通过了解底层K线的处理机制,我们可以根据自己的需求编写新的计算逻辑,或者修改现有的指标算法,以实现更加符合我们策略的指标。
容错处理:了解底层K线的处理机制可以帮助我们进行容错处理。在实际应用中,K线数据可能存在缺失、异常等情况,这可能会对计算结果产生较大影响。通过了解底层处理机制,我们可以针对特定的情况进行容错处理,例如使用默认值或插值法填补缺失数据,排除异常值等,以提高策略的稳定性和鲁棒性。
综上所述,了解底层K线的处理机制对于理解技术指标的计算过程、优化算法、策略定制和容错处理都非常重要。这样我们可以更好地理解和应用量化交易中的技术指标,提升交易策略的效果和稳定性。
今天,我们以移动平均值的计算为例,手写一个源码,探讨背后的k线处理机制。
function HANDMA(records, period) {
var MA = []; // 存储移动平均值的数组
// 遍历数据数组
for (var i = 0; i < records.length; i++) {
if (i < period-1) {
MA.push(NaN); // 添加NaN
} else {
var sum = 0;
// 计算每个数据点之前 period 个数据的和
for (var j = i - period + 1; j <= i; j++) {
sum += records[j].Close;
}
// 计算当前数据点的移动平均值
var ma = sum / period;
// 存储移动平均值到数组中
MA.push(ma);
}
}
return MA;
}
function main(){
var c = KLineChart({})
while (true){
exchange.SetContractType('rb888');
var records = exchange.GetRecords();
MA_20_hand = HANDMA(records, 20);
MA_20 = TA.MA(records, 20);
Log('手动移动平均数据',MA_20_hand);
Log('移动平均数据',MA_20);
for (var i = 0 ; i < records.length ; i++) {
var bar = records[i]
c.begin(bar)
c.plot(MA_20_hand[i], "手动移动平均", {overlay: true}) // 画在图表主图
c.plot(MA_20[i], "移动平均", {overlay: true}) // 画在图表主图
c.close()
}
}
}
根据代码显示,移动平均值函数接受两个参数:records(包含K线数据的数组)和period(移动平均的周期)。函数通过遍历数据数组来计算移动平均值,并将结果存储在一个数组MA中。
具体的计算步骤如下:
-
创建一个空数组MA,MA是moving average,移动平均值,用于存储移动平均值。
-
遍历数据数组records。
-
如果当前索引i小于周期period-1,将nan添加到MA数组中,表示该位置的移动平均值暂时无法计算。否则,计算当前数据点之前period个数据的和。通过一个内部循环,从i - period + 1到i的范围,累加这些数据点的收盘价。
-
计算当前数据点的移动平均值,即将上一步计算的和除以周期period。
-
将移动平均值存储到MA数组中。
-
完成遍历后,返回MA数组作为结果。
在函数定义完成后,我们在主函数中,获取k线数据,然后调用HANDMA(records, 20)和TA.MA(records, 20)函数分别计算了手动移动平均数据和移动平均数据,并将结果打印输出。使用KLineChart函数,我们进行了两条均线的呈现。
在回测结果中可以看到,在9点到9点30分之间,移动平均值设置20为周期,前20分钟内,移动平均值都是空值,当收集够足够的数量后,开始进行指标的计算。现成的指标和手动的指标两条线是重合的,证明我们的计算是没有问题的。
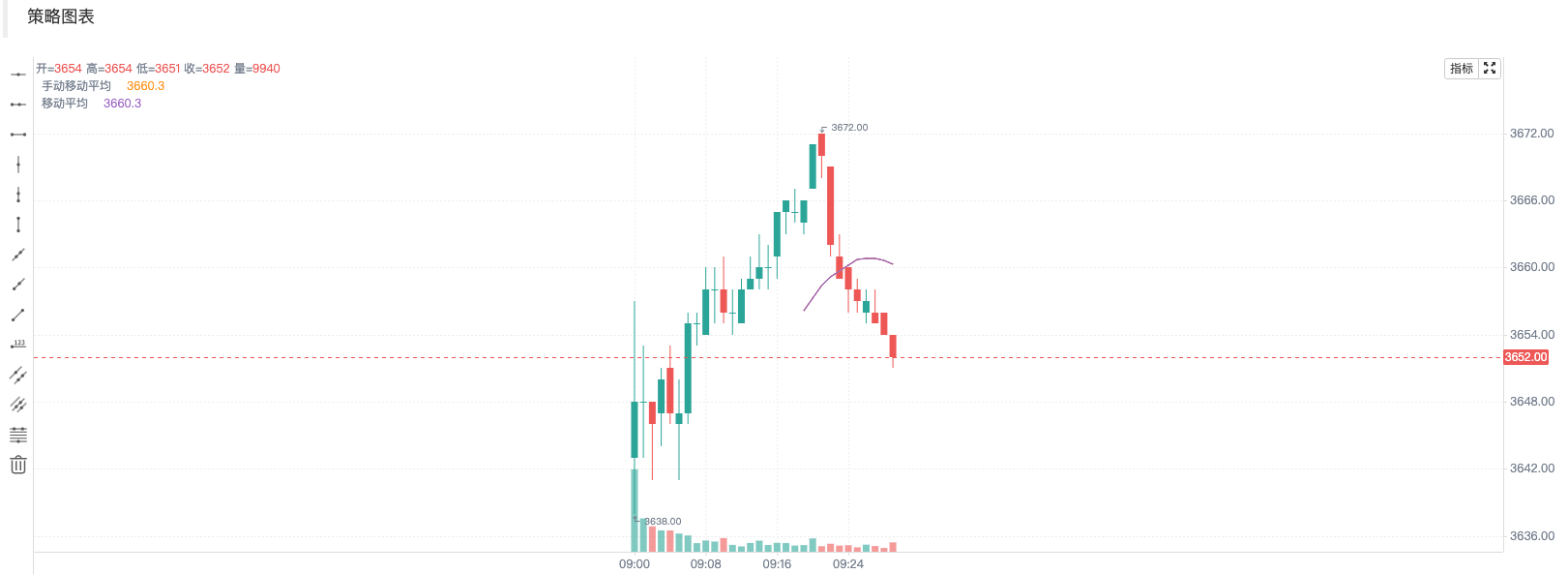
这里我们需要理解下,MA数组和K线数据的对应关系:
records是一个数组,其中包含了伴随时间流的多个K线记录。每个K线记录都包含了开盘价、最高价、最低价和收盘价等信息。
MA是一个用于存储移动平均值的数组,虽然在图中没有呈现,但是通过打印MA数组,它的长度与records数组相同。在计算移动平均之前的周期(period)内,MA数组中的元素都是空值(null)。这些空值用来表示移动平均计算过程中前期数据不足的情况。当然,我们也可以选择其他的处理方式来处理数据不足的情况。例如,可以使用累计周期的均值作为移动平均的替代值,或者使用其他的填充值来表示未达到k线数量的移动平均值。
在给定的代码中,当索引i小于移动平均的周期period-1时,也就是前期数据不足以计算移动平均值时,将nan添加到MA数组中。MA数组的第一个有效值元素对应着records数组中的第period个元素的移动平均值,然后伴随k线的更新,新的ma值被对应计算出来。这样就能确保移动平均值和K线数据之间的一一对应关系。通过这种对应关系,我们可以方便地从MA数组中获取每个K线数据对应的移动平均值,进行进一步的分析和处理。
代码确实不复杂,但重要的是我们需要深入理解底层K线的处理机制。当我们使用K线进行技术指标计算时,无论是MACD还是RSI,我们需要了解底层K线是如何被使用的,以及指标结果与K线的对应关系。我们可以更好地理解技术指标的计算原理和应用场景。
在同时,了解底层K线的处理机制可以帮助我们理解K线数据的结构和含义,以及K线的时间周期和采样频率。这对于正确地解读技术指标的结果至关重要。我们需要知道每个指标结果对应的是哪个K线数据,以及指标结果如何随着时间的推移而更新。我们可以看到,当我们设定的周期为分钟时,MA计算返回的结果也是以分钟作为周期。但是需要温馨提醒下,在最后一根k线没有完成的时候,MA最后的一个值也是不固定的。
当然这只是使用k线计算移动平均值的小例子,希望从这份代码出发,大家可以理解k线处理的底层机制,更进一步的帮助我们更好地理解一些复杂技术指标的计算过程。如果有兴趣的话,指标计算源码在fmz平台是公开的(https://www.youquant.com/bbs-topic/8293),我们可以参考学习,并根据实际需求,进行更适合我们交易理念的定制化的指标计算和策略优化。
- 商品期货中PnL损益指标的应用
- 机器学习(二):商品期货中的VAR模型应用
- 浅谈期货人经过的几层认知
- 在FMZ平台搭建多因子模型(二):展期收益率单因子模型
- 机器学习(一):聚类分析在商品期货市场中的应用
- 在FMZ平台搭建多因子模型(一):多因子策略介绍
- FMZ股票模拟盘程序化交易策略:布林带多品种策略
- 商品期货量化交易实践系列课程
- 使用KLineChart函数让策略画图设计更加简单
- 一根k线的故事
- 以平均K线图(Heikin-Ashi)算法为例教你写FMZ扩展指标库
- 量化策略马后炮:浅谈量化交易中的过拟合问题
- 让策略程序真正并发执行,给JavaScript策略增加系统底层多线程支持
- 牛刀小试:用Pine语言画出顶背离和底背离指标观察系统
- 一年只做四手的量化交易策略,年化140%,你喜欢吗?
- 期货市场血亏3300元,怒花半小时写出21行年化100%的玻璃期货策略
- 商品期货量化交易必学的知识--基于tick数据推算逐笔交易历史
- 当FMZ遇到ChatGPT,记一次使用AI来辅助学习量化交易的尝试
- 商品期货跨品种套利模型
- 教你使用python实现一个止盈止损类库